
During covid (as all good stories start) a good friend and I got very into making cocktails together over Facetime. We called it ‘Booze-day Tuesdays‘, later simply Tuesdays. If we ever open a cocktail bar, that’s its name.
Though, we quickly realised that tracking our mixology journey wasn’t a job for pen and paper… and I resolved to make a PHP/MySQL site that looked straight out of 1996:

I hated it. But what I hated more was that it cost me money to run (as an AWS EC2 machine), despite only being used once a week to remind myself what goes in basic cocktails.
I recently thought about alternative, and minimalist, technology approaches, and decided to – as a practical experiment – limit myself to recreating the site using only a single S3 Bucket.
S3 Buckets are an Amazon AWS document storage service, they’re cheap and have a nice API for fetching and uploading files.
While they can store .HTML and .JS files that a browser can open directly, they can’t run any application code you put in them… and therefore are not designed to singularly house dynamic applications.
A dynamic application, by definition, is one whose content can change dynamically based on user interaction, preferences, or other factors, rather than displaying the same content to every visitor.
It’s broadly considered that they require a web application server to process logic and data, not just a web server that serves static files. In 2025, both these tasks might fall to one consolidating program – but they are distinct capabilities.
My cocktail site, while basic, is a dynamic application. The site is public but edit functionality (for creating cocktails, uploading images, etc) is restricted behind a login.
In the absence of a web application server, our .HTML and .JS files hosted on S3 must take on more than just the usual UI responsibilities. They also need to handle user authentication for editing content, manage all other application logic, and ensure that any data changes – like adding a new cocktail – are securely written back to the S3 bucket for others to see.
At first glance, this might sound like we’re just building a typical Single Page Application (SPA). SPAs are web applications that – you guessed it – live on a single page, but deliver a multi-page experience by dynamically updating the DOM and routing internally. They typically rely on APIs or backend services to fetch and mutate data without triggering full-page reloads. They have logic-heavy front-ends.
In our case, however, while we do shift more logic to the front-end just like an SPA, we’re doing it for a very different reason: because we have no traditional backend at all.
What we’re trying to do, then, is build a dynamic application using only static content delivery. And in theory, that’s impossible – for two key reasons:
1/ Storage Mutations (Create/Update/Delete). Web-servers (like Apache or Lighttpd) don’t provide a means to add, modify, or delete content – they just let you read it. At their core, they’re just HTTP engines – they serve files and accept requests, but they don’t persist data. If you want to turn an incoming request into a saved file, you need application-level logic
2/ Authentication/Authorisation. Even if web servers could handle uploads or data storage directly, they don’t natively manage user identity or enforce permissions. There’s no built-in way to say “user Alice can upload to /data, but not Bob.” That kind of access control requires integration with an authentication system – again, requiring application logic.
However, with these two fundamental building blocks, it’s possible to migrate all other application logic to the browser – and build almost any application using only static content delivery for the rest.
Back to S3.
S3 supports a ‘Static website hosting‘ mode – but, due to trade-offs I’ll explain shortly, we won’t use it.
Furthermore, S3 isn’t ‘dumb storage’ like a CD. It’s an abstracted storage service that you can authenticate to and control bucket data via an API. It has those building blocks we need.
The plan:
Step 1/ Choose a Data Format – The actual data/content of the website (like, say, what goes into an Espresso Martini) will be obtained from a flat file cocktails.json. This holds all my site data: cocktail details, their ingredients, and URLs to images (also stored on the S3). Essentially utilising a .JSON blob as a database. Fetching the file is like calling an API, except there’s no intelligence around which data is returned – it’s everything. I’ve scripted the process of converting the previous MySQL database into the cocktails.json file.
Step 2/ Configure the S3 Bucket – Everything in my app is public information; the .HTML/.JS, .JSON, and images… all public (to read at least). So we’ll open up the bucket to full read access from the internet – scary.
Step 3/ Build the UI – We’ve gone with a minimalist (though still better) UI. Now, we can filter cocktails based on various criteria, and ‘pin’ user favourites – which are remembered in LocalStorage.
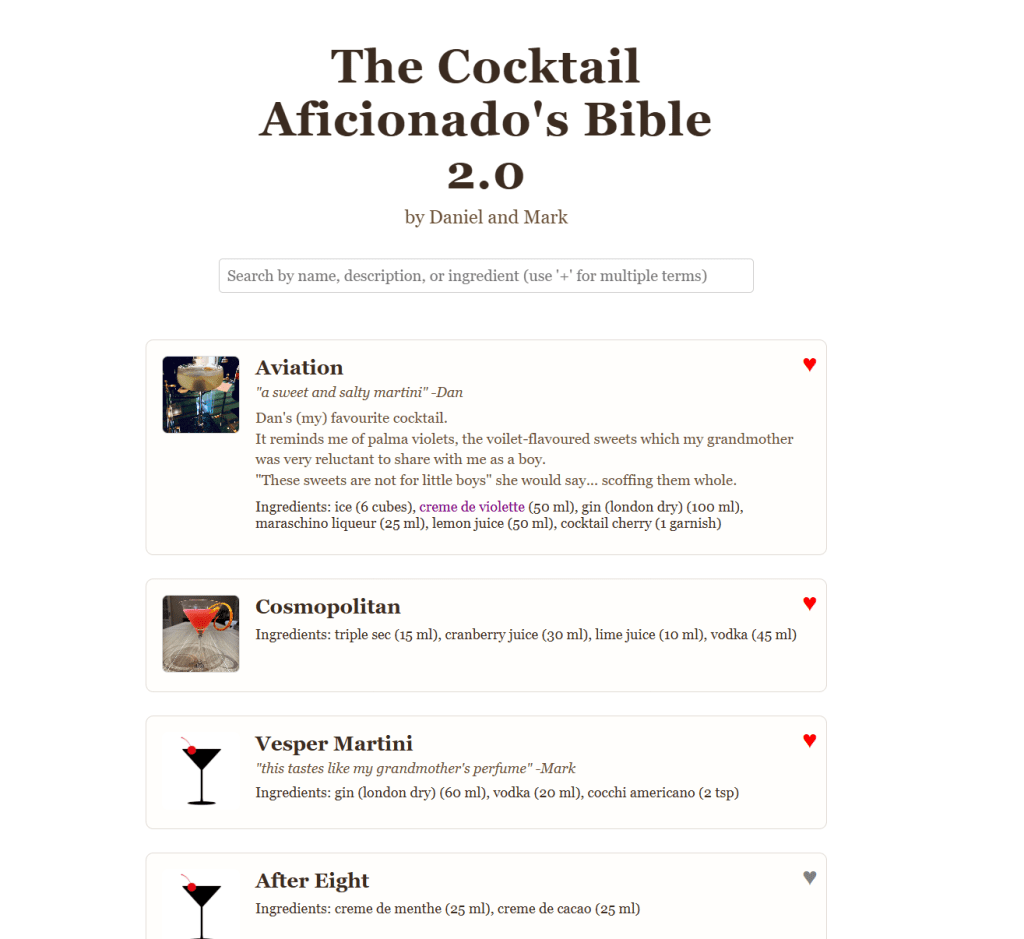
Step 4/ Secure Client-Side Writes – Now comes the tricky part. How can our front-end Create/Update/Delete content in the S3? (i.e. cocktail information in cocktails.json, or cocktail images, etc).
Well, 11 years ago Amazon created a JavaScript SDK so that browsers could use the AWS API directly, and therefore S3. Although, even in their celebratory posts about this JavaScript SDK… we were warned that hardcoding AWS credentials (secret keys) into a webpage, while possible, was insecure – which instantly destroyed many potential use-cases. It is possible these days to use SAML or Web Identity Federation (WIF) for AWS authentication – then grab a short-lived credential, but that would require the use of more AWS services beyond just S3.
So, to do this, we’ll do exactly as we’ve been instructed not to – we’ll embed a secret key to our S3 bucket directly in plain sight in the page’s JavaScript. This key will allow our front-end to push back updates to the application data (cocktails.json, etc) to the bucket.
To avoid our S3 bucket being compromised in a hot minute however, we’ll use a cool trick to make this ‘secure enough’.
We’ll use the Web Crypto API (built into all modern browsers) to encrypt our AWS credentials via AES–GCM. And to make sure that we use a secure key for the encryption, we’ll use a password and send that through the PBKDF2 ‘key derivation function’ (which spits out something akin to a hash).
password -> key derivation function -> encryption
We can now store the encrypted AWS Credentials in our site instead. We’ll require the user to provide the password to decrypt those credentials in the browser for any S3 operations, without which the AWS SDK cannot authenticate and function (and our Bucket data is safe).
Adding, editing, or deleting a cocktail is an operation limited to either my friend or I. So here’s the form I added to the UI for those updates:
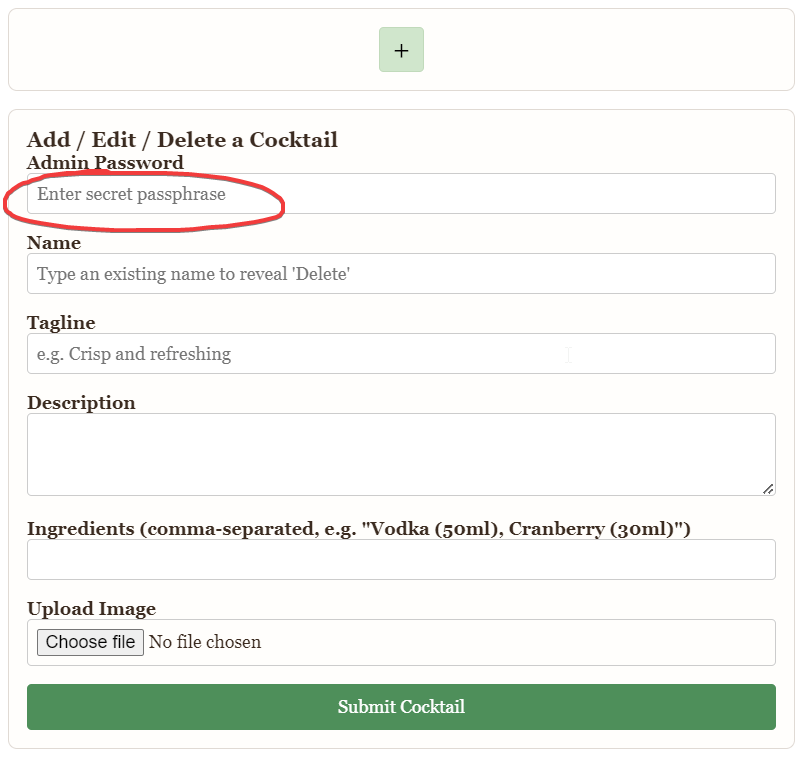
And here’s the decryption function used to resolve the AWS token for use on the bucket:
async function decryptString(encryptedData, iv, password) {
const encoder = new TextEncoder();
const decoder = new TextDecoder();
// Derive a key from the password
const keyMaterial = await window.crypto.subtle.importKey(
"raw",
encoder.encode(password),
{ name: "PBKDF2" },
false,
["deriveKey"]
);
// Use a fixed salt "thecocktailaficionadosbible"
const key = await window.crypto.subtle.deriveKey(
{
name: "PBKDF2",
salt: encoder.encode("thecocktailaficionadosbible"),
iterations: 100000,
hash: "SHA-256"
},
keyMaterial,
{ name: "AES-GCM", length: 256 },
false,
["decrypt"]
);
After any AWS SDK operation is performed, the SDK doesn’t need to hold onto the secrets in memory anymore, and we should remove them:
//Creds in .accessKeyId and .secretAccessKey
AWS.config.credentials = null;
And that’s it. Through some clever encryption, we’ve got a “website” that is dynamic, and sits solely on S3.
Step 5/ A Place To Call Home – There is one last thing we need to do. We need a domain.
You can’t point Route53 domains directly to an S3 resource – you need to front the S3 bucket with another AWS service first. However, when we create a bucket… the bucket has an immediately available URI in the format:
{the bucket name + AWS region + amazonaws.com}. e.g. https://BUCKETNAME.s3.eu-west-2.amazonaws.com.
Not only does this URI contain our bucket name verbatim, but it has TLS transparently set up. It’s free, the certificate is issued direct from Amazon, and we’ll never have to do anything to ensure it’s there. It just is. Moreover, you can’t mess up (or have compromised) the DNS of a setup you don’t even have access to.

Honestly, for the sake of vanity – it feels weird that we would forego some of the resiliency that this setup offers by injecting ourselves into this setup and adding more complexities.
As mentioned, S3 supports a ‘Static website hosting‘ mode. All it does is allows you to configure a Default .HTML file, and an Error .HTML file. As Amazon don’t want you hosting apps under amazonaws.com and giving you certificates for free, this comes at the expense of the TLS not being automatic – and needing to be setup with CloudFront. For this reason, we have an additional niggle with our setup that we have to browse direct to:
https://BUCKETNAME.s3.eu-west-2.amazonaws.com/index.html
Do we care? Not really, we’ve had browser bookmarks since 1993.
🧠 Conclusion:
I found it interesting to realise that CRUD and authentication primitives are foundational for dynamic applications, and that S3 is a surprisingly capable home for them.
I also spent far too long musing on the definition of a dynamic application. Given so much time is spent in cybersecurity offering opinions on the contrasted risks between static & dynamic web applications – its unsatisfying how imprecise the definitions available are. It might be less important to know exactly where the line is drawn between them – than it is to say ‘would an architecture prohibit dynamic functionality?’ – if it does, it’s static.
I also found it interesting to review the security considerations in using a service domain (bucket URL) as the home for an application. On one hand, we’re removed from all potential DNS issues here, we’re getting a certificate for free (forever), and we’ll never have to think about it – on the other – these URLs (while easily bookmarked) are not memorable or appealing.
Cost 💸:
In the last 3 months, I’ve maintained requests to this application to under 1000. Given pricing is $0.0004 per 1,000 requests for GETs, and $0.005 per 1,000 requests for PUTs – this means there was no billable cost at all. That’s Booze-day engineering at its finest.

Technical Caveats 🧰:
1/ Technically we are using a few other ‘services’ within AWS, for example IAM roles, Security groups etc. Although nothing billable.
2/ I acknowledge that S3 provides a huge leg-up over a simply static web server. I surmise that we would need these features in future web servers for this architecture (in its truest form) to be viable.
Where could you take this? 🔮:
While i’m not suggesting you should, you really could take this setup to extremes and make large, rich applications with users and role-based-access-controls (RBAC) just on S3. You could create write-locking files to avoid data corruption, and keep a versioned backup of all changed files. You could create per-user AWS credentials to limit access to specific bucket ‘folders’ (prefixes).
Security 🔒:
1/ Obviously this architecture puts a lot of extra pressure on cryptography. Since the access to sensitive data can only be limited through client-side cryptographic controls. A person will always have direct access to a credential (at least in an encrypted form) that provides a level of access beyond that which they are permitted. Since cryptography algorithms weaken over time – there’s very little in the way of defence in depth.
2/ As an Application Security professional – I realise the knee-jerk reaction from other professionals is that this is non-standard approach and therefore insecure. I offer that you consider the threat model.
Could you – as an attacker – access the key? crack it?
And how would you consider making this type of application more secure?
I’m keen to know your thoughts, and views on how this paradigm could be pushed further.
-hiburn8
For completeness, i’m linking our simple website for you to review the code [please ignore our childish comments]:
https://cocktailaficionadosbible.s3.eu-west-2.amazonaws.com/index.html

Leave a comment